
Automated RAG System Evaluations: Practical Insights

Jun 15, 2025
10 min read
In my previous article, I discussed various aspects and areas to consider when evaluating a Retrieval Augmented Generation (RAG) system. While that piece offered a broad overview of RAG system evaluation, covering various testing areas and practical examples, this article focuses on providing deeper insights into automating RAG system evaluations. It also highlights the immense benefits that automation brings. It will guide and practical steps that you can use and start from scratch even if you don’t have much knowledge of different evaluation frameworks.
As someone with a background in UI, API, and performance automation, it was a natural progression for me to explore automating RAG testing. However, I quickly realized it wasn’t as straightforward as I initially thought.
Why Automated RAG Testing Isn’t Straightforward🤔
Automating RAG testing presents unique complexities compared to traditional software testing:
Response Variance: Unlike deterministic systems, RAG models can produce varied responses for the same query, even if the underlying meaning is identical.
Semantic Equivalence vs. Exact Match: The same question might yield different wording in responses, making a simple one-to-one comparison with a “ground truth” answer ineffective. We cannot solely rely on exact string matching.
Effective Test Data Creation: Validating the accuracy of RAG systems effectively requires robust test data. This necessitates a “source of truth” and a corresponding set of questions, along with their expected answers derived from that truth.
Approaches to Automated Evaluation
The Rule-Based Approach
In a rule-based approach, we validate RAG answer accuracy using traditional metrics like cosine similarity. This involves comparing the RAG system’s response with the source-of-truth answer and applying a threshold. Parameters such as string matching and embedding distance are used to calculate similarity. If the similarity exceeds a predefined percentage, the response is considered accurate; otherwise, it’s flagged as inaccurate.

Common Examples of Rule Based Techniques
Problem with Rule-Based Approaches:
The main issue here is that sometimes responses are factually correct but have significantly different wording, leading to a low similarity score. This can result in unnecessary false negatives and, in some cases, false positives. The limitation lies in its inability to discern meaning, focusing only on word or embedding similarity.
LLM as a Judge: A More Nuanced Approach
This is where the “LLM as a Judge” approach shines. Large Language Models (LLMs) possess reasoning capabilities, enabling them to compare responses based on their meaning rather than just relying on superficial wording. This semantic understanding greatly enhances the accuracy of evaluations.
Another significant benefit of this automated approach is the ability to test RAG systems on a massive scale. Manually evaluating a RAG system against, say, 10,000 documents is practically impossible. An automated LLM-based evaluation, however, can swiftly process a vast number of examples, ensuring quality and accuracy across large datasets.
How to Use an LLM as a Judge: The LLM Evaluator
To leverage an LLM for testing, we typically use the term “LLM Evaluator.” You can either create your own custom LLM Evaluator or utilize pre-built ones offered by various frameworks. Popular examples include LangChain, Ragas, and MLFlow, which provide robust functionalities for this purpose. Many frameworks offer built-in parameters like correctness, relevance, toxicity, faithfulness (or groundedness), context relevance, context recall, and context precision. However, specific use cases may necessitate building custom evaluators tailored to unique criteria.
An LLM Evaluator is essentially a well-crafted prompt designed to read inputs and outputs, then evaluate the correctness of the RAG system’s response based on defined rules.
Below I have provided a high level Automated RAG Evaluation Pipeline
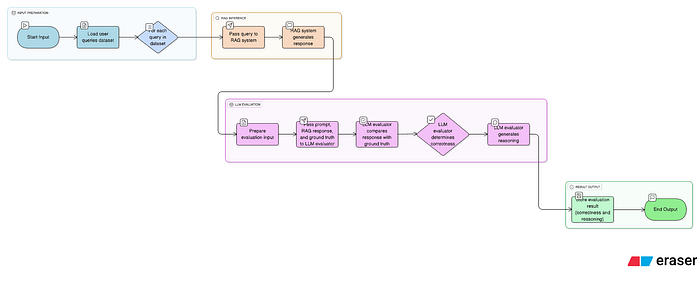
Automated RAG Evaluation Pipeline
Components of an Effective Evaluation Prompt
To write an effective evaluation prompt, consider including the following components:
Purpose: Provide a brief background to the LLM, clearly defining its role and the specific evaluation task it needs to perform.
Inputs: Specify the data the LLM will receive, which typically includes the question sent to the RAG system, the ground truth answer, and the actual output received from the RAG system.
Evaluation Rules: Define a clear set of rules or criteria that the evaluator should use to review the inputs and determine if the response is correct or not.
Examples (Positive and Negative): For tricky or nuanced scenarios, it’s beneficial to include both positive and negative examples to guide the LLM’s understanding of desired and undesired outputs.
Result Format: Clearly state the desired output format for the evaluation result (e.g., JSON, plain string). Crucial elements of the result usually include whether the answer is correct and the reasoning behind the decision, though this can be tweaked based on your use case.
Example LLM Evaluator Prompt:
You are an AI assistant designed to evaluate the correctness of RAG system responses by comparing them against a known ground truth.
Your goal is to determine if the RAG response accurately answers the user's question, is relevant to the question, and does not contain any hallucinated information.
You are an AI assistant designed to evaluate the correctness of RAG system responses by comparing them against a known ground truth.
Your goal is to determine if the RAG response accurately answers the user's question, is relevant to the question, and does not contain any hallucinated information.
QUESTION: {question}
GROUND_TRUTH: {ground_truth}
RAG_RESPONSE: {rag_response}
EVALUATION_RULES:
Correctness: The RAG_RESPONSE must directly answer the QUESTION and align with the facts presented in the GROUND_TRUTH. It should not contradict or misrepresent the GROUND_TRUTH.
Relevance: The RAG_RESPONSE must be directly relevant to the QUESTION asked. It should not include extraneous information that is not requested or implied by the question.
Completeness: The RAG_RESPONSE should cover all key aspects of the answer implied by the QUESTION, as found in the GROUND_TRUTH. It should not be a partial answer if a more complete one is available in the GROUND_TRUTH.
Conciseness: While complete, the RAG_RESPONSE should be concise and to the point, avoiding unnecessary verbosity.
No Hallucination: The RAG_RESPONSE must only contain information derived from the GROUND_TRUTH. Any information not supported by the GROUND_TRUTH will be considered a hallucination.
EXAMPLES:
Positive Example 1:
QUESTION: What is the capital of France?
GROUND_TRUTH: The capital of France is Paris.
RAG_RESPONSE: Paris is the capital city of France.
EVALUATION:
{
"is_correct": true,
"reasoning": "The RAG response correctly identifies Paris as the capital of France, which directly aligns with the ground truth and answers the question accurately."
}
Negative Example 1: QUESTION: What is the largest ocean on Earth? GROUND_TRUTH: The Pacific Ocean is the largest and deepest of Earth's five oceans. RAG_RESPONSE: The Atlantic Ocean is the largest.
EVALUATION:
{
"is_correct": false,
"reasoning": "The RAG response incorrectly states the Atlantic Ocean is the largest. The ground truth clearly indicates the Pacific Ocean is the largest. This is a factual error."
}
RESULT_FORMAT: Provide your evaluation in a JSON object with the following keys: is_correct (boolean): true if the RAG_RESPONSE adheres to all EVALUATION_RULES, false otherwise. reasoning (string): A clear, concise explanation of why the RAG_RESPONSE is deemed correct or incorrect, specifically referencing the violated or satisfied rules.
The Crucial Role of Test Data
One important factor in using evaluators is availability test data. Test data for RAG systems usually have two main components at minimum, and you can add more as per your requirements: normally a question and a pair of ground truth (the source from where the question can be answered). So when a prompt is given to a system, we also have the source of truth that we can compare the RAG application output against.
To get a dataset, we have three options:
User queries: Once the system is in production, we can collect queries from user feedback and use them as our dataset.
Manually curating: Going through the documents that are ingested in the RAG system and writing questions, noting down the source of truth that you think should answer the question you have created.
Synthetic dataset curation: The first two approaches are fine, but for large-scale testing where you may have thousands of documents, they may not be that effective. To ensure comprehensive testing, we will require some synthetic dataset curation mechanism. This approach is especially helpful for systems where the RAG system is constantly updated. In such cases, new data sources are frequently added or modified. Manually keeping track of these changes can become difficult over time. So, automatic dataset curation will help a lot in such cases as well.
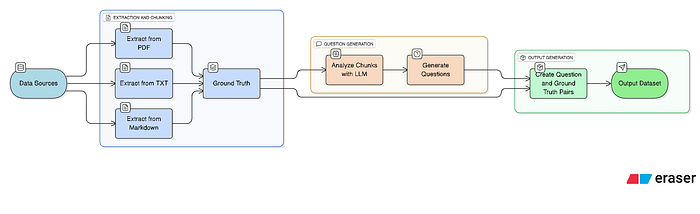
Synthetic Dataset Curation
How to do it?
To be able to do it, you will have the following components:
Methods/Functions for Chunk Extraction from Data Sources:You will require functions that are capable of reading information from the data sources supported in your RAG systems. The purpose of doing this is to scrape data from the source in larger chunks that can be used as a ground truth. It’s like if you are manually testing, you will go through the document and find chunks of information based on which you will ask questions to the system. For example, if your RAG application has a data source of PDFs, your method should be able to go through it and extract information from pages and store it in some format like CSV or JSON or any other.
Questions Generator:Next up, you will require a method/function that should read the chunks of information extracted in Step 1 and, based on it, generate a set of questions. For this, you will require an LLM and prompt engineering that reads the information and creates an appropriate question from it. The prompt you give to generate questions should have the following parts:
Purpose: As mentioned in the evaluator, clearly define the purpose of the prompt
Inputs: The chunk Extracted that will be used to generate questions
Rules: Based on which the LLM will generate questions using the input.
Result: How you want the output of the prompt to show you the question, either in the form of JSON or a plain string or whatever.
This way, you will have a large set of questions and their ground truth that is not generated but directly extracted from the source of truth. This will enable you to test your LLM application at a faster pace and at a larger scale and will ensure high quality.
Example LLM Questions Generator Prompt:
You are an expert content creator tasked with generating diverse and relevant questions based on provided text chunks. Your goal is to create questions that can be directly and fully answered by the information within the given chunk.
CHUNK_TEXT: {chunk_of_text_from_data_source}
RULES_FOR_QUESTION_GENERATION:
Generate 3–5 distinct questions for each CHUNK_TEXT.
Each question must be directly answerable only by the information present in the CHUNK_TEXT. Do not introduce outside knowledge.
Vary the question types (e.g., factual recall, simple inference, definitions).
Ensure questions are clear, concise, and grammatically correct.
Avoid ambiguous questions or questions that require subjective interpretation.
The questions should be designed to test a RAG system's ability to retrieve and generate accurate answers from the source.
EXAMPLES:
---
Positive Example 1: CHUNK_TEXT: "The Amazon River, located in South America, is the largest river by discharge volume of water in the world, averaging 209,000 cubic meters per second. It flows through Brazil, Peru, and Colombia."
GENERATED_QUESTIONS:
JSON
[
{
"question": "Which continent is the Amazon River located in?",
"ground_truth_source": "The Amazon River, located in South America"
},
{
"question": "What is the average discharge volume of water for the Amazon River?",
"ground_truth_source": "averaging 209,000 cubic meters per second."
},
{
"question": "Name three countries the Amazon River flows through.",
"ground_truth_source": "It flows through Brazil, Peru, and Colombia."
}
]
Negative Example 1 (Demonstrates rule violation): CHUNK_TEXT: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It was completed in 1889."
GENERATED_QUESTIONS:
JSON
[
{
"question": "Who designed the Eiffel Tower?",
"ground_truth_source": "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It was completed in 1889."
}
]
RESULT_FORMAT: Provide the generated questions as a JSON array of objects. Each object should have two keys:
question (string): The generated question.
ground_truth_source (string): The exact snippet from the CHUNK_TEXT that answers the question.
By implementing this pipeline, you can efficiently generate a large set of questions paired with their direct ground truth, which is extracted rather than manually generated. This capability allows you to test your RAG application at a faster pace and significantly larger scale, ultimately ensuring higher quality and accuracy across your entire dataset.
Conclusion
So, here we go! In this article, we’ve learned how to effectively evaluate RAG systems using automation and how to write Good LLM Evaluators as well. Finally, I also mentioned one of the most important step of dataset generation. With that, I’ve attached a sample repository or implementation that has some methods for dataset curation and an LLM evaluator that you can use as a starting point for further work.
Link to Repository https://github.com/wisamulhaq/RAG_Automation.git