
LLM as a Judge: Future of Evaluation? A Complete Guide for Software Engineers

Jul 27, 2025
8 min read
Ever wondered if AI can judge AI? This article explores how and why we use large language models (LLMs) to evaluate the outputs of other LLMs or systems. It’s a practical guide for software professionals, engineers, QA specialists, and ML practitioners — regardless of whether you’re working with GPT, Claude, Mistral, or any other model.
We’ll walk through:
What it means for an LLM to act as a judge
Why traditional evaluation methods fall short
Benefits, challenges, and real-world use cases
Best practices for safe, fair, and accurate evaluation
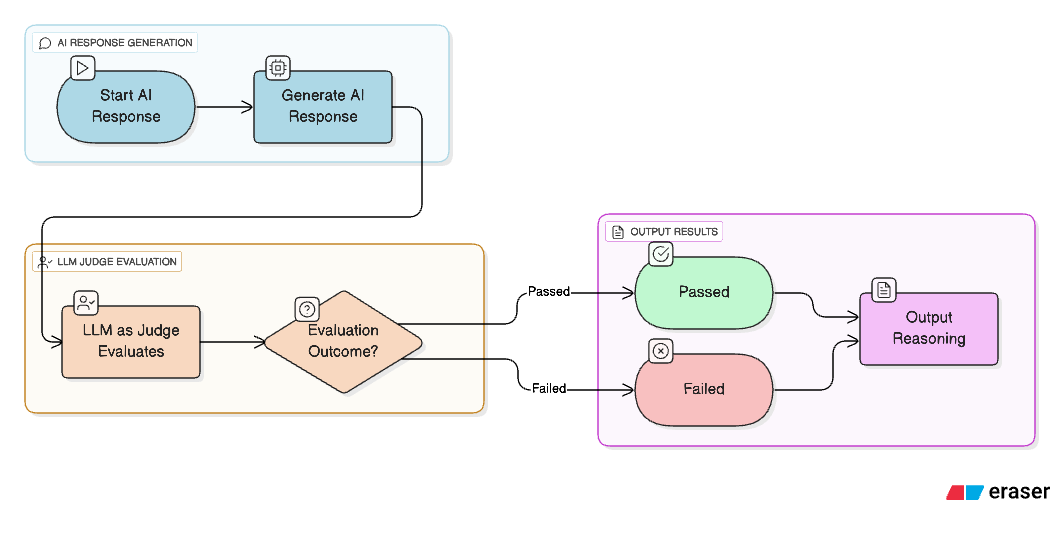
What is LLM-as-a-Judge?
In simple terms, LLM-as-a-Judge is an evaluation technique where we use an LLM to evaluate the outputs of an LLM Application.
It answers questions like:
Was the response factually correct?
Was it relevant to the question?
Was it helpful or complete?
The judging LLM is prompted to give structured, Boolean judgments (✅ or ❌), or even grade output on a scale, along with reasoning for its decision. Typically, the judgment prompt will include the original question, the expected answer or ground truth (if any), and the actual response generated. This is particularly helpful when aiming to improve our system through LLM-based evaluation. Reasoning, a key strength of LLMs, serves as a powerful tool — one that is uniquely available when using LLMs as judges.
This technique is especially useful in non-deterministic scenarios like open-ended answers where traditional unit tests or rule-based evaluation fail.
Why Traditional Evaluation Techniques Fall Short?

Manual Human Evaluation
The most common evaluation approach today is assigning a human reviewer or subject matter expert (SME) to manually evaluate AI-generated responses. While this method brings human understanding and context into the process, it has significant limitations:
Bias: LLM outputs are often subjective. Similarly, human reviewers carry inherent subjectivity due to their individual preferences, backgrounds, and understanding. This introduces evaluation noise, leading to false positives or false negatives in judgments.
Expensive: Human evaluation is costly hiring, training, and managing a large group of evaluators becomes financially impractical, especially when scaling the evaluation process across thousands of responses.
Scalability: The human-based approach does not scale well. As your dataset grows, so do the costs, time, and risks of inconsistent evaluation results due to increased bias and fatigue.
Automated Rule-Based Evaluation
So, if manual efforts aren’t enough, the natural next step is automation. One popular method is rule-based or similarity-based evaluation, such as:
Cosine Similarity
Embedding distance comparisons
String or token overlap
Threshold-based matching
These techniques involve comparing AI responses to a pre-defined ground truth and checking whether they cross a similarity threshold.
But here’s why this approach breaks down:
Threshold Variability: Due to the non-deterministic nature of LLMs, similar questions can yield slightly different but equally valid answers. Setting a fixed threshold becomes tricky.
Lack of Reasoning: These methods only give a numeric score. If a response fails, you don’t know why. There’s no explanation or traceability of logic. Human reviewers still need to jump in and dig through the response manually.
No Contextual Understanding: These techniques treat the text as tokens, not meaning. They fail to assess tone, creativity, coherence, helpfulness, or the nuanced structure of the answer. That’s a dealbreaker for LLM-based apps like chatbots, educational assistants, or creative generators, where human-like context and tone matter just as much as factual correctness.
No Ground Truth: There can be cases where you don’t have a ground truth. In such cases these techniques do not provide much help at all.
When to Use What?
LLM-as-a-Judge is best suited for non-deterministic applications where outputs may vary in form but still be valid (e.g., chatbots, search, summarization).
Use LLM-based evaluation when:
Responses are open-ended and not easily matched word-for-word
Manual evaluation is too costly or slow
You want to iterate rapidly on model quality
Traditional metrics like BLEU or ROUGE are misleading
You’re evaluating reasoning, helpfulness, or domain-specific accuracy

Do not use LLM As a Judge when we know our application will have objective response and we know the response. In such cases traditional techniques works the best. Traditional API testing, UI testing do not require using LLM As a Judge.
A Checklist for selecting LLM As a Judge
Use this checklist to determine if LLM-as-a-Judge is appropriate for your evaluation:
🔘 Is the output subjective?
🔘 Do traditional techniques miss key quality signals?
🔘 Would an LLM-based approach be more cost-effective than humans?
🔘 Do you need to iterate frequently on evaluations?
🔘 Is manual evaluation impractical due to volume?
🔘 Do you need to scale evaluations automatically?
🔘 Is the evaluation task complex or multi-dimensional?
If most of these answers are yes, LLM-as-a-Judge might be the right fit.
Advantages of Using LLM as a Judge
Here’s why teams across the industry are moving toward LLM-as-a-Judge:
Scalable Evaluation Run thousands of tests programmatically across datasets or API responses.
Handles Subjectivity Especially useful for evaluating tone, relevance, completeness, or insightfulness.
Iterative Feedback Use judgments to improve both the LLM responses and the evaluation prompt itself.
Customizable Criteria Define your own rubric — factuality, helpfulness, clarity, domain knowledge, etc.
Risks & Challenges of LLM-as-a-Judge
LLMs aren’t perfect judges. Common issues include:
Model Bias If you use GPT-4 as both generator and evaluator, it may favor its own responses over others like Claude.
Long Responses In long, multi-topic responses, the LLM might miss key incorrect details, leading to false positives.
Authority Bias Citing a famous source followed by an incorrect statement may be incorrectly marked as accurate.
Positional Bias LLMs can overlook incorrect information if it’s embedded in the middle of an otherwise correct response.
Aesthetic Bias LLMs might favor well-written or pleasing text, even if factually incorrect.
How to Mitigate Risks
Here’s what you can do to improve accuracy and fairness in LLM-as-a-Judge setups:
Prompt Engineering
Be explicit about what you’re evaluating.
Ask for a binary answer + reasoning (
Is this correct? Yes/No. Explain.).Set up a persona or system instruction clearly (e.g., “You are an impartial judge”).
Give the required details to your prompt. Think of it like onboarding a human to the task.
Chain-of-Thought Reasoning
Break down the problem statement in steps instead of prompting it to do everything in one go.
Ask the model to first explain its judgment, then output the final score.
This reduces hallucinated scores and improves transparency.
Use Multiple Judges
Try evaluation from two different LLMs and check for consistency.
Add Human Oversight
Especially important for high-stakes domains like healthcare or finance.
Standard Tooling
Consider using open-source tools like:
OpenAI Evals — built-in test framework
Ragas — for RAG evaluation pipelines
Galileo — for end 2 end evaluation pipelines
Example LLM Evaluator Prompt:
You are an AI assistant designed to evaluate the correctness of RAG system responses by comparing them against a known ground truth.
Your goal is to determine if the RAG response accurately answers the user's question, is relevant to the question, and does not contain any hallucinated information.
QUESTION: {question}
GROUND_TRUTH: {ground_truth}
RAG_RESPONSE: {rag_response}
EVALUATION_RULES:
Correctness: The RAG_RESPONSE must directly answer the QUESTION and align with the facts presented in the GROUND_TRUTH. It should not contradict or misrepresent the GROUND_TRUTH.
Relevance: The RAG_RESPONSE must be directly relevant to the QUESTION asked. It should not include extraneous information that is not requested or implied by the question.
Completeness: The RAG_RESPONSE should cover all key aspects of the answer implied by the QUESTION, as found in the GROUND_TRUTH. It should not be a partial answer if a more complete one is available in the GROUND_TRUTH.
Conciseness: While complete, the RAG_RESPONSE should be concise and to the point, avoiding unnecessary verbosity.
No Hallucination: The RAG_RESPONSE must only contain information derived from the GROUND_TRUTH. Any information not supported by the GROUND_TRUTH will be considered a hallucination.
EXAMPLES:
Positive Example 1:
QUESTION: What is the capital of France?
GROUND_TRUTH: The capital of France is Paris.
RAG_RESPONSE: Paris is the capital city of France.
EVALUATION:
{
"is_correct": true,
"reasoning": "The RAG response correctly identifies Paris as the capital of France, which directly aligns with the ground truth and answers the question accurately."
}
Negative Example 1: QUESTION: What is the largest ocean on Earth? GROUND_TRUTH: The Pacific Ocean is the largest and deepest of Earth's five oceans. RAG_RESPONSE: The Atlantic Ocean is the largest.
EVALUATION:
{
"is_correct": false,
"reasoning": "The RAG response incorrectly states the Atlantic Ocean is the largest. The ground truth clearly indicates the Pacific Ocean is the largest. This is a factual error."
}
RESULT_FORMAT: Provide your evaluation in a JSON object with the following keys: is_corr
Final Questions You May Have
1. What’s the role of humans in this evaluation?
LLM-as-a-Judge does not mean we eliminate human input. Instead, humans — especially Subject Matter Experts (SMEs) — should:
Review edge cases
Provide feedback on misjudgments
Adjust prompts or criteria
Supervise and continually improve the judge LLM
Think of the LLM as your evaluation assistant, not your only reviewer.
2. Isn’t it wrong to use the same LLM for generating and evaluating responses?
Good question — but not necessarily.
LLMs behave based on their task instruction or persona. The same model can act as a helpful assistant in one prompt and as a critical evaluator in another.
That said, it’s still a good idea to:
Experiment with different models for judging and responding
Use structured prompts and chain-of-thought
Validate against human-labeled datasets occasionally
3. Where can I learn more and try this out?
No worries, I’ve got you covered.
Blog on RAG Evaluation: 👉 RAG Evaluation Simplified
Hands-on Evaluation Pipeline Code: 👉 GitHub — RAG_Automation
You’ll find sample use cases, prompts, and a working setup you can fork or extend.
Summary
LLM-as-a-Judge is one of the most promising approaches to automated, scalable, and nuanced evaluation in the LLM ecosystem.
When used responsibly — with good prompting, human oversight, and cross-validation — it can drastically speed up your QA, model fine-tuning, or research workflows.